loguru 简单方便的 Python 日志记录管理模块
#编程技术 2020-11-18 11:37:00 | 全文 3483 字,阅读约需 7 分钟 | 加载中... 次浏览👋 相关阅读
- No 1. 什么是 Pandas & Pandas 能干啥?
- python:Pandas里千万不能做的5件事
- python:如何从 URL 中快速提取域名?
- Python3.7实现自动刷博客访问量(只需要输入用户id)
- Pycharm 专业版配置自动同步代码至服务器
这是个啥?
在 Python 中,一般情况下我们可能直接用自带的 logging 模块来记录日志,包括我之前的时候也是一样。在使用时我们需要配置一些 Handler、Formatter 来进行一些处理,比如把日志输出到不同的位置,或者设置一个不同的输出格式,或者设置日志分块和备份。但其实个人感觉 logging 用起来其实并不是那么好用,其实主要还是配置较为繁琐。
但有这么一个库,它不仅能够减少繁琐的配置过程还能实现和 logging 类似的功能,同时还能保证日志记录的线程进程安全,又能够和 logging 相兼容,并进一步追踪异常也能进行代码回溯。这个库叫 loguru —— 一个专为像我这样懒人而生日志记录库。
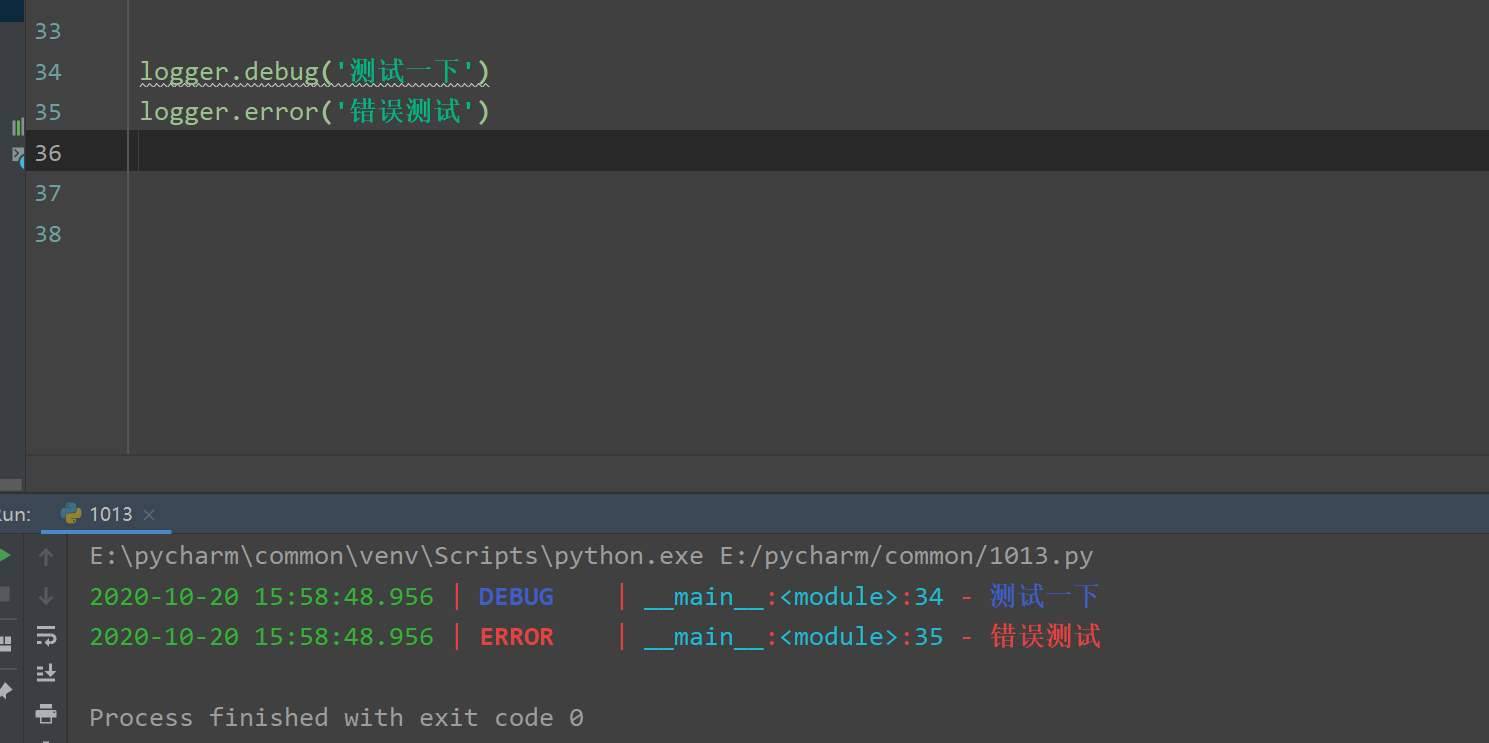
loguru 库的使用可以说是十分简单,我们直接可以通过导入它本身封装好的 logger 类就可以直接进行调用。
怎么装?
前提是你装好了 Python,没有 Python 你也用不到这个模块啊喂

命令行执行以下命令
pip install loguru
怎么用?
logger 本身就是一个已经实例化好的对象,如果没有特殊的配置需求,那么自身就已经带有通用的配置参数; 它的用法和 logging 库输出日志时的用法一致
你只需要先这样
from loguru import logger
再这样
logger.debug('调试消息')
logger.info('普通消息')
logger.warning('警告消息')
logger.error('错误消息')
logger.critical('严重错误消息')
logger.success('成功调用')
然后
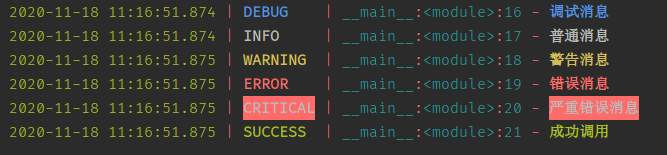
怎么样,是不是狠简单?

大佬用法
当然,loguru 也像 logging 一样为我们提供了其他可配置的部分,但相比于 logging 每次要导入特定的 handler 再设定一些 formatter 来说是更为「傻瓜化」了。
使用基本的 add() 方法就可以对 logger 进行简单的配置,这些配置有点类似于使用 logging 时的 handler。这里简单提及一下比较常用的几个。
写入文件
在不指定任何参数时,logger 默认采用 sys.stderr 标准错误输出将日志输出到控制台(console)中;但在 linux 服务器上我们有时不仅让其输出,还要以文件的形式进行留存,那么只需要在第一个参数中传入一个你想要留存文件的路径字符串即可。就像这样:
from loguru import logger
import os
logger.add(os.path.expanduser("~/Desktop/testlog.log"))
logger.info("hello, world!")
这样在你的桌面上就会直接出现相应的 testlog.log 日志文件了。
日志拆分、留存、压缩与清理
通常来说如果程序或服务的量级较大,那么就可以通过集成的日志平台或数据库来对日志信息进行存储和留存,后续有需要的话也方便进行日志分析。
但对我们个人或者一些中小型项目来说,通常只需要以文件的形式留存输出的日志即可。
尽管我们需要将日志写入到相应的文件中,如果是少量的日志那还好,但是如果是日志输出或记录时间较长的情况,那么单个日志文件就十分之大,倘若仍然是将日志都写入到一个文件中,那么当日志中的内容增长到一定数量时我们想要读取并查找相应的部分时就十分困难。这时候我们就需要对日志文件进行拆分、留存、压缩,甚至在必要时及时进行清理。
基于以上,我们可以通过对 filter、rotation 、compression 和 retention 四个参数进行设定来满足我们的需要:
rotation 参数能够帮助我们将日志记录以大小、时间等方式进行分割或划分。
logger.add("file_1.log", rotation="500 MB") ## 自动循环过大的文件
logger.add("file_2.log", rotation="12:00") ## 每天中午创建新文件
logger.add("file_3.log", rotation="1 week") ## 一旦文件太旧进行循环
比如下边这种写法
mport os
from loguru import logger
LOG_DIR = os.path.expanduser("~/Desktop/logs")
LOG_FILE = os.path.join(LOG_DIR, "file_{time}.log")
if os.path.exits(LOG_DIR):
os.mkdir(LOG_DIR)
logger.add(LOG_FILE, rotation = "200KB")
for n in range(10000):
logger.info(f"test - {n}")
结果就是
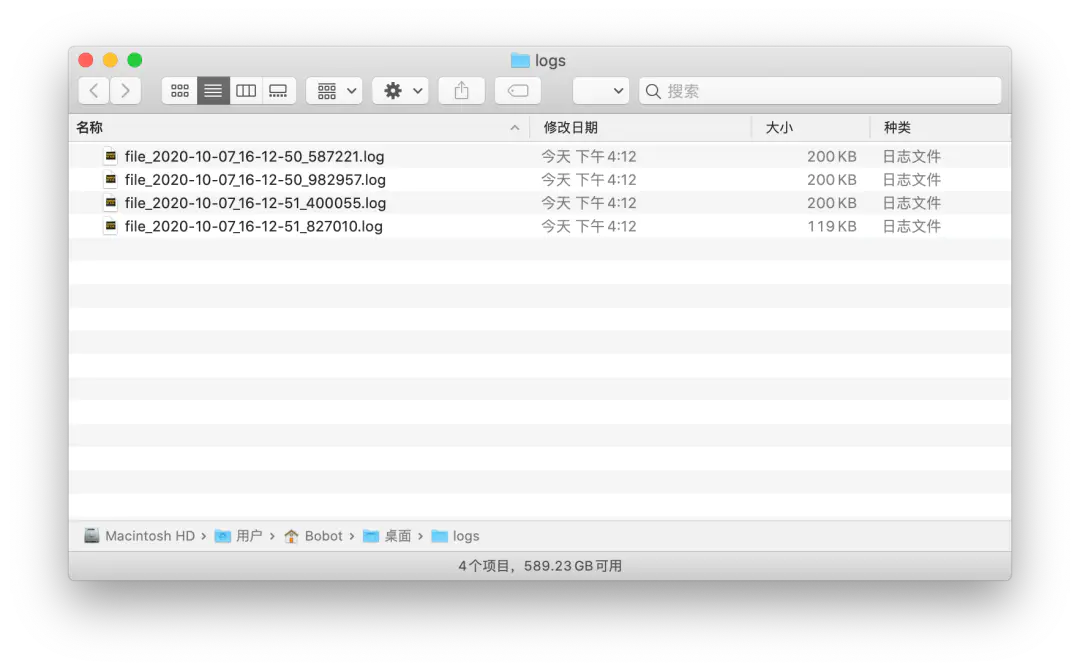
随着分割文件的数量越来越多之后,我们也可以进行压缩对日志进行留存,这里就要使用到 compression 参数,该参数只要你传入通用的压缩文件扩展名即可,如 zip、tar、gz 等。
import os
from loguru import logger
LOG_DIR = os.path.expanduser("~/Desktop/logs")
LOG_FILE = os.path.join(LOG_DIR, "file_{time}.log")
if os.path.exits(LOG_DIR):
os.mkdir(LOG_DIR)
logger.add(LOG_FILE, rotation = "200KB", compression="zip")
for n in range(10000):
logger.info(f"test - {n}")
从结果可以看到,只要是满足了 rotation 分割后的日志文件都被直接压缩成了 zip 文件,文件大小由原本的 200kb 直接减少至 10kb,对于一些磁盘空间吃紧的 Linux 服务器来说是则是很有必要的。
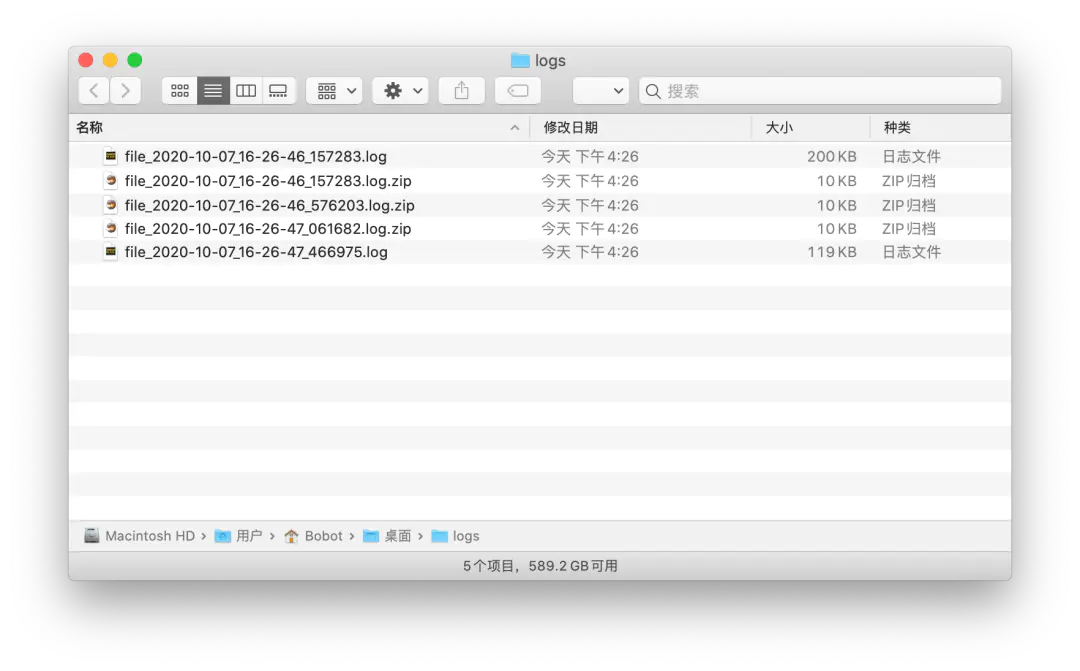
当然了,如果你不想对日志进行留存,或者只想保留一段时间内的日志并对超期的日志进行删除,那么直接使用 retention 参数就好了。
这里我们可以将之前的结果随意复制 N 多份在 logs 文件夹中,然后再执行一次加上 retension 参数后代码:
from loguru import logger
LOG_DIR = os.path.expanduser("~/Desktop/logs")
LOG_FILE = os.path.join(LOG_DIR, "file_{time}.log")
if not os.path.exists(LOG_DIR):
os.mkdir(LOG_DIR)
logger.add(LOG_FILE, rotation="200KB",retention=1)
for n in range(10000):
logger.info(f"test - {n}")
对 retention 传入整数时,该参数表示的是所有文件的索引,而非要保留的文件数,这里是个反直觉的小坑,用的时候注意一下就好了。所以最后我们会看到只有两个时间最近的日志文件会被保留下来,其他都被直接清理掉了。
filter 参数能够对日志文件进行过滤,利用这个特性我们可以按照日志级别分别存入不同的文件。
from loguru import logger
logger.add("logs/jobs-info-{time:YYYY-MM-DD}.log", filter=lambda record: "INFO" in record['level'].name)
logger.add("logs/jobs-error-{time:YYYY-MM-DD}.log", filter=lambda record: "ERROR" in record['level'].name)
通过上边的配置
INFO 级别的日志会存入 logs/jobs-info-2020-11-11.log 文件
ERROR 级别的文件则会存入 logs/jobs-error-2020-11-11.log 文件
查看详细配置:https://loguru.readthedocs.io/en/stable/api/logger.html#file
序列化
如果在实际中你不太喜欢以文件的形式保留日志,那么你也可以通过 serialize 参数将其转化成序列化的 json 格式,最后将导入类似于 MongoDB、ElasticSearch 这类数 NoSQL 数据库中用作后续的日志分析。
from loguru import logger
import os
logger.add(os.path.expanduser("~/Desktop/testlog.log"), serialize=True)
logger.info("hello, world!")
最后保存的日志都是序列化后的单条记录:
{
"text": "2020-10-07 18:23:36.902 | INFO | __main__:<module>:6 - hello, world\n",
"record": {
"elapsed": {
"repr": "0:00:00.005412",
"seconds": 0.005412
},
"exception": null,
"extra": {},
"file": {
"name": "log_test.py",
"path": "/Users/Bobot/PycharmProjects/docs-python/src/loguru/log_test.py"
},
"function": "<module>",
"level": {
"icon": "\u2139\ufe0f",
"name": "INFO",
"no": 20
},
"line": 6,
"message": "hello, world",
"module": "log_test",
"name": "__main__",
"process": {
"id": 12662,
"name": "MainProcess"
},
"thread": {
"id": 4578131392,
"name": "MainThread"
},
"time": {
"repr": "2020-10-07 18:23:36.902358+08:00",
"timestamp": 1602066216.902358
}
}
}
通过 bind() 添加额外属性来结构化日志
from loguru import logger
logger.add("file.log", format="{extra[ip]} {extra[user]} {message}")
context_logger = logger.bind(ip="192.168.0.1", user="someone")
context_logger.info("Contextualize your logger easily")
context_logger.bind(user="someone_else").info("Inline binding of extra attribute")
context_logger.info("Use kwargs to add context during formatting: {user}", user="anybody")
file.log
192.168.0.1 someone Contextualize your logger easily
192.168.0.1 someone_else Inline binding of extra attribute
192.168.0.1 anybody Use kwargs to add context during formatting: anybod
结合 bind(special=True) 和 filter 对日志进行更细粒度的控制
from loguru import logger
logger.add("special.log", filter=lambda record: "special" in record["extra"])
logger.debug("This message is not logged to the file")
logger.bind(special=True).info("This message, though, is logged to the file!")
special.log
2020-07-22 17:06:40.998 | INFO | __main__:<module>:5 - This message, though, is logged to the file!
时间格式
from loguru import logger
logger.add('file.log', format='{time:YYYY-MM-DD HH:mm:ss} | {level} | {message}', encoding='utf-8')
logger.debug('调试消息')
file.log
2020-07-22 17:18:08 | DEBUG | 调试消息
解析器
通常需要从日志中提取特定信息, parse() 可用处理日志和正则表达式。
## -*- coding: utf-8 -*-
from loguru import logger
from dateutil import parser
logger.add('file.log', format='{time} - {level.no} - {message}', encoding='utf-8')
logger.debug('调试消息')
pattern = r'(?P<time>.*) - (?P<level>[0-9]+) - (?P<message>.*)' ## 带命名组的正则表达式
caster_dict = dict(time=parser.parse, level=int) ## 匹配)
for i in logger.parse('file.log', pattern, cast=caster_dict):
print(i)
## {'time': datetime.datetime(2020, 7, 22, 17, 33, 12, 554282, tzinfo=tzoffset(None, 28800)), 'level': 10, 'message': '璋冭瘯娑堟伅'}
logger.parse() 没有参数 encoding,本人测试解析中文会乱码
异步、线程安全、多进程安全
默认为线程安全,但不是异步或多进程安全的,添加参数 enqueue=True 即可:
logger.add("somefile.log", enqueue=True)
协程可用 complete() 等待
异常追溯
当异常和错误不可避免时,最好的方式就是让我们知道程序到底是哪里出了错,或者是因为什么导致错误,这样才能更好地让开发人员及时应对并解决。
loguru 集成了一个名为 better_exceptions 的库,不仅能够将异常和错误记录,并且还能对异常进行追溯,这里是来自一个官网的例子
只需要添加参数 backtrace=True 和 diagnose=True 就会显示整个堆栈跟踪,包括变量的值
import os
import sys
from loguru import logger
logger.add(os.path.expanduser("~/Desktop/exception_log.log"), backtrace=True, diagnose=True)
def func(a, b):
return a / b
def nested(c):
try:
func(5, c)
except ZeroDivisionError:
logger.exception("What?!")
if __name__ == "__main__":
nested(0)
最后在日志文件中我们可以得到以下内容:
File "/Users/Bobot/PycharmProjects/docs-python/src/loguru/log_test.py", line 20, in <module>
nested(0)
└ <function nested at 0x7fb9300c1170>
> File "/Users/Bobot/PycharmProjects/docs-python/src/loguru/log_test.py", line 14, in nested
func(5, c)
│ └ 0
└ <function func at 0x7fb93010add0>
File "/Users/Bobot/PycharmProjects/docs-python/src/loguru/log_test.py", line 10, in func
return a / b
│ └ 0
└ 5
ZeroDivisionError: division by zero
使用catch()装饰器 或 上下文管理器
- 装饰器
from loguru import logger
@logger.catch
def func(x, y, z):
return 1 / (x + y + z)
if __name__ == '__main__':
func(0, 1, -1)
- 上下文管理器
from loguru import logger
def func(x, y, z):
return 1 / (x + y + z)
with logger.catch():
func(0, 1, -1)
输出
2020-11-18 11:20:39.149 | ERROR | __main__:<module>:22 - An error has been caught in function '<module>', process 'MainProcess' (3596), thread 'MainThread' (30992):
Traceback (most recent call last):
> File "E:/SVN/wangcheng/canal\test.py", line 22, in <module>
func(0, 1, -1)
└ <function func at 0x000001DBDD1DFAE8>
File "E:/SVN/wangcheng/canal\test.py", line 18, in func
return 1 / (x + y + z)
│ │ └ -1
│ └ 1
└ 0
ZeroDivisionError: division by zero
与 Logging 完全兼容(Entirely Compatible)
尽管说 loguru 算是重新「造轮子」,但是它也能和 logging 库很好地兼容。到现在我们才谈论到 add() 方法的第一个参数 sink。
这个参数的英文单词动词有「下沉、浸没」等意,对于外国人来说在理解上可能没什么难的,可对我们国人来说,这可之前logging 库中的 handler 概念还不好理解。好在前面我有说过,loguru 和 logging 库的使用上存在相似之处,因此在后续的使用中其实我们就可以将其理解为 handler,只不过它的范围更广一些,可以除了 handler 之外的字符串、可调用方法、协程对象等。
loguru 官方文档对这一参数的解释是:
object in charge of receiving formatted logging messages and propagating them to an appropriate endpoint.
翻译过来就是「一个用于接收格式化日志信息并将其传输合适端点的对象」,进一步形象理解就像是一个「分流器」。
import logging.handlers
import os
import sys
from loguru import logger
LOG_FILE = os.path.expanduser("~/Desktop/testlog.log")
file_handler = logging.handlers.RotatingFileHandler(LOG_FILE, encoding="utf-8")
logger.add(file_handler)
logger.debug("hello, world")
当然目前只是想在之前基于 logging 写好的模块中集成 loguru,只要重新编写一个继承自 logging.Handler 类并实现了 emit() 方法的 Handler 即可。
import logging.handlers
import os
import sys
from loguru import logger
class InterceptHandler(logging.Handler):
def emit(self, record):
try:
level = logger.level(record.levelname).name
except ValueError:
level = record.levelno
frame, depth = logging.currentframe(), 2
while frame.f_code.co_filename == logging.__file__:
frame = frame.f_back
depth += 1
logger.opt(depth=depth, exception=record.exc_info).log(level, record.getMessage())
logging.basicConfig(handlers=[InterceptHandler()], level=0)
def func(a, b):
return a / b
def nested(c):
try:
func(5, c)
except ZeroDivisionError:
logging.exception("What?!")
if __name__ == "__main__":
nested(0)
后结果同之前的异常追溯一致。而我们只需要在配置后直接调用 logging 的相关方法即可,减少了迁移和重写的成本。
via:
- 别再手动配置logging了大家都在用loguru - 简书 https://www.jianshu.com/p/5aead7b6a7a9
- Python日志库loguru——轻松记日志,一个函数搞定_XerCis的博客-CSDN博客 https://xercis.blog.csdn.net/article/details/107516039
- 官方文档 https://loguru.readthedocs.io/en/stable/